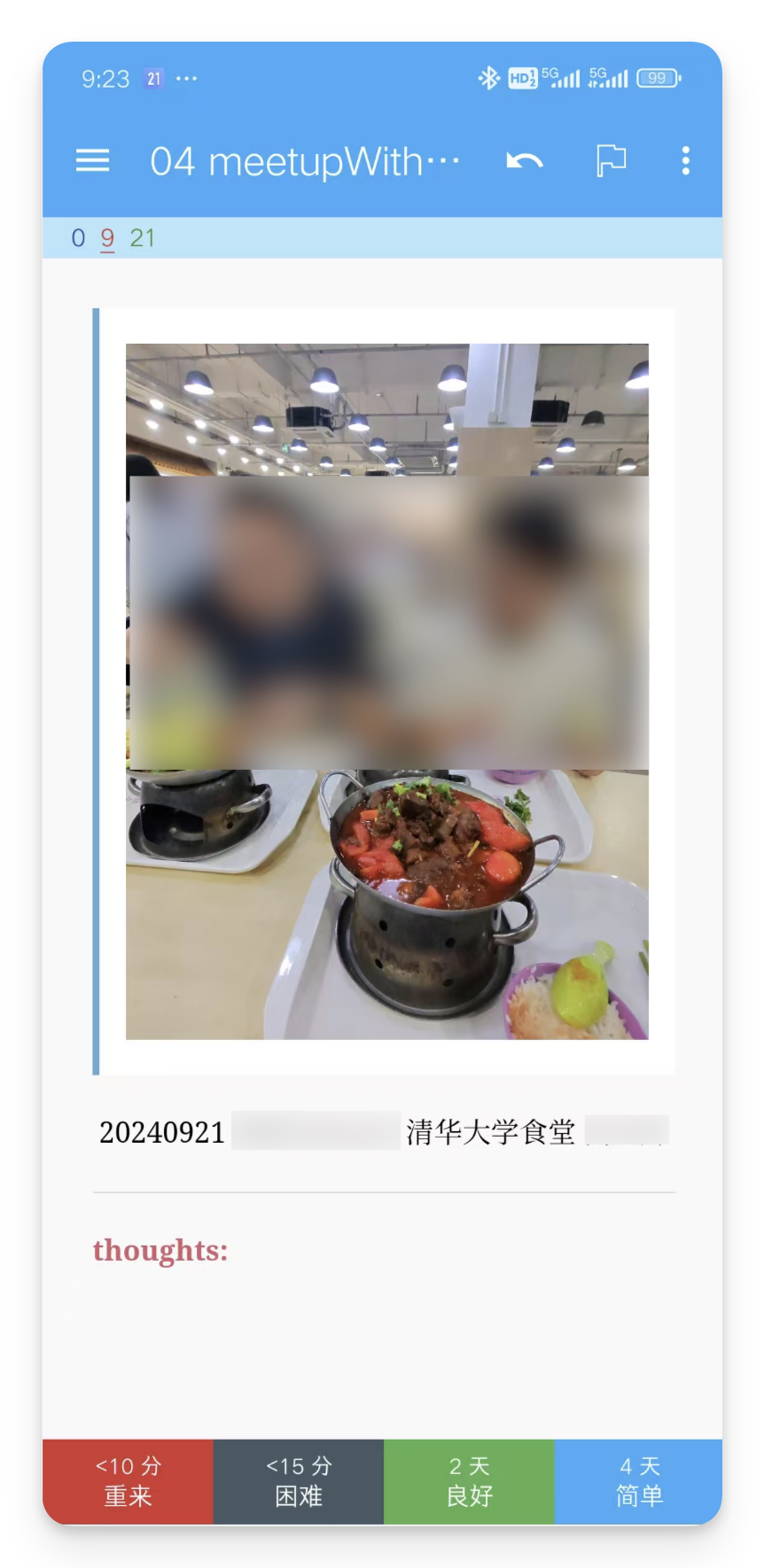
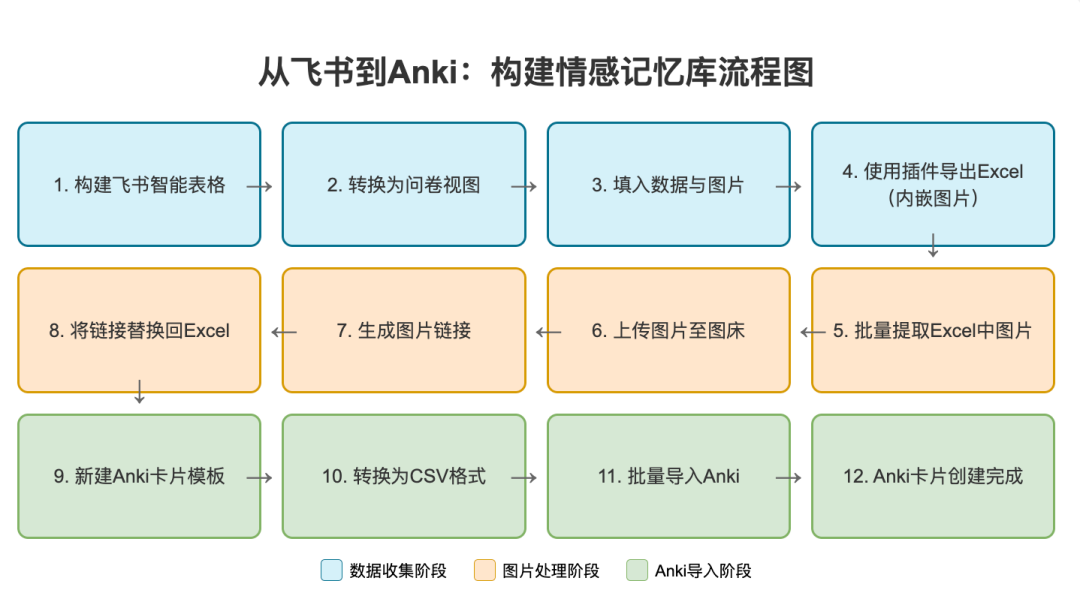
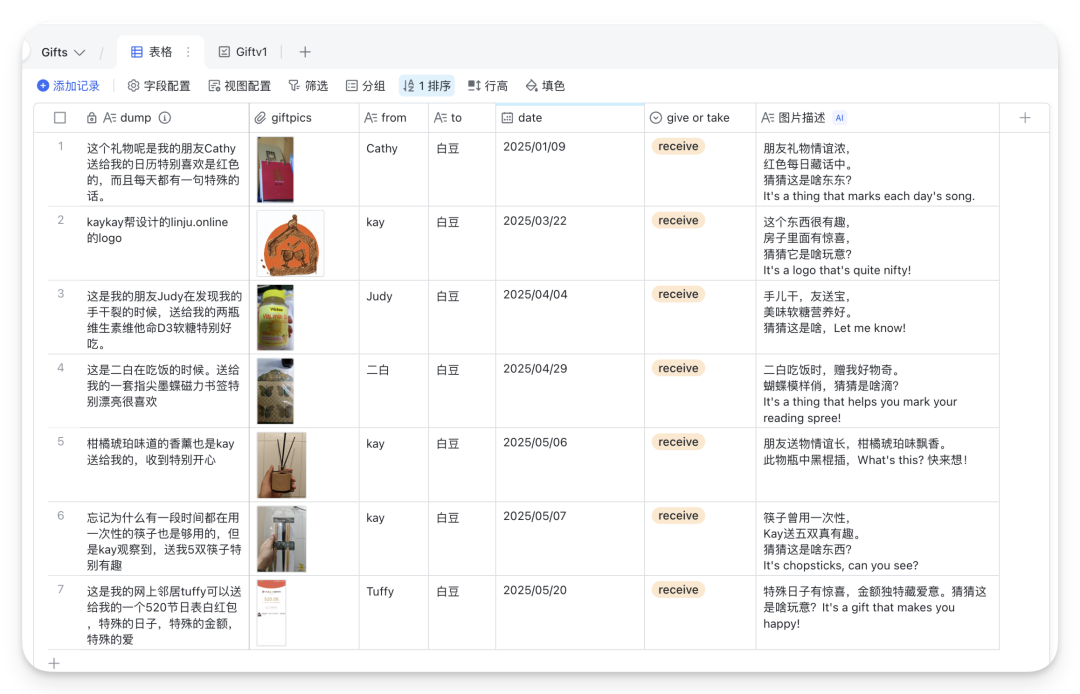
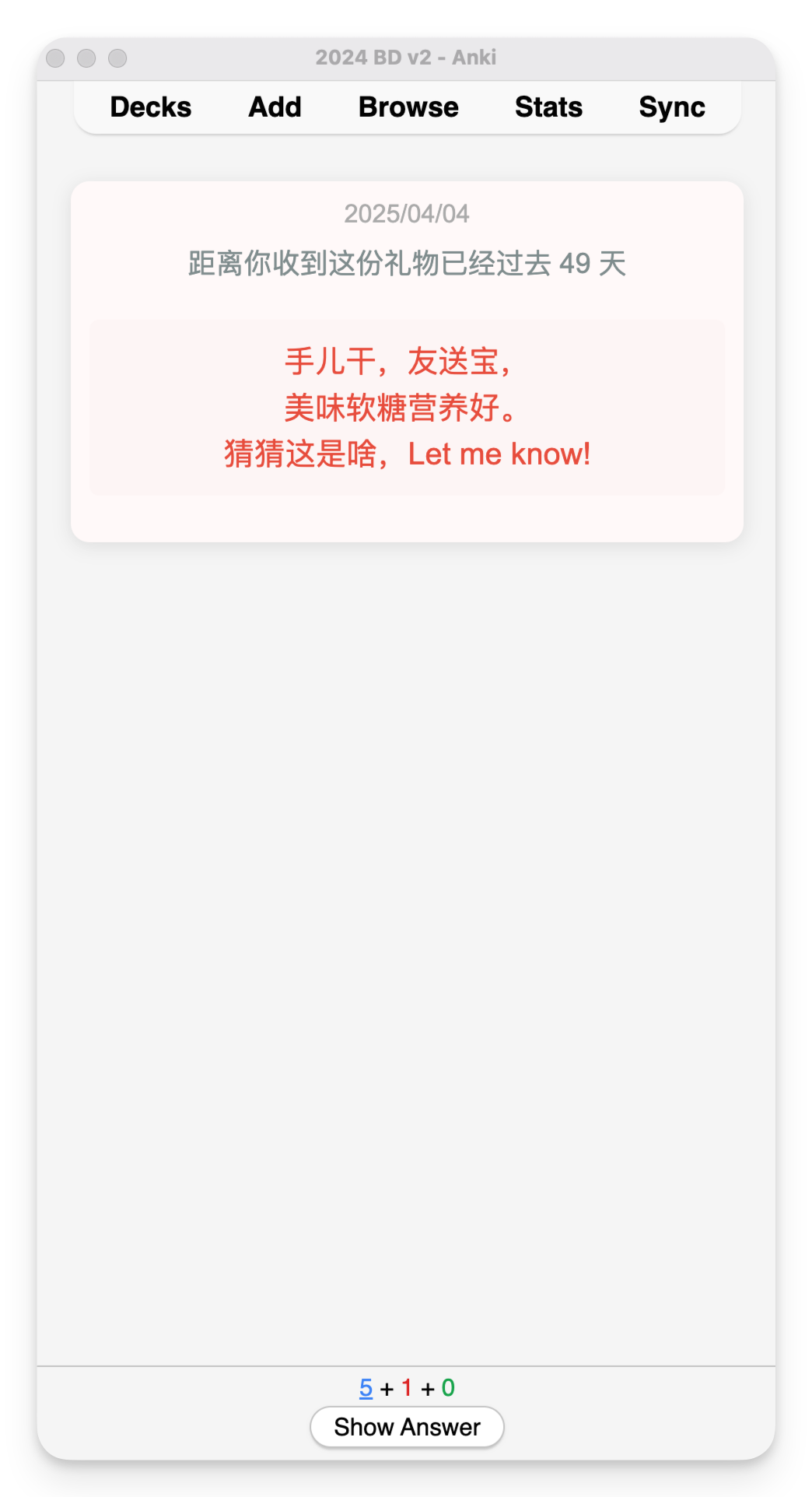
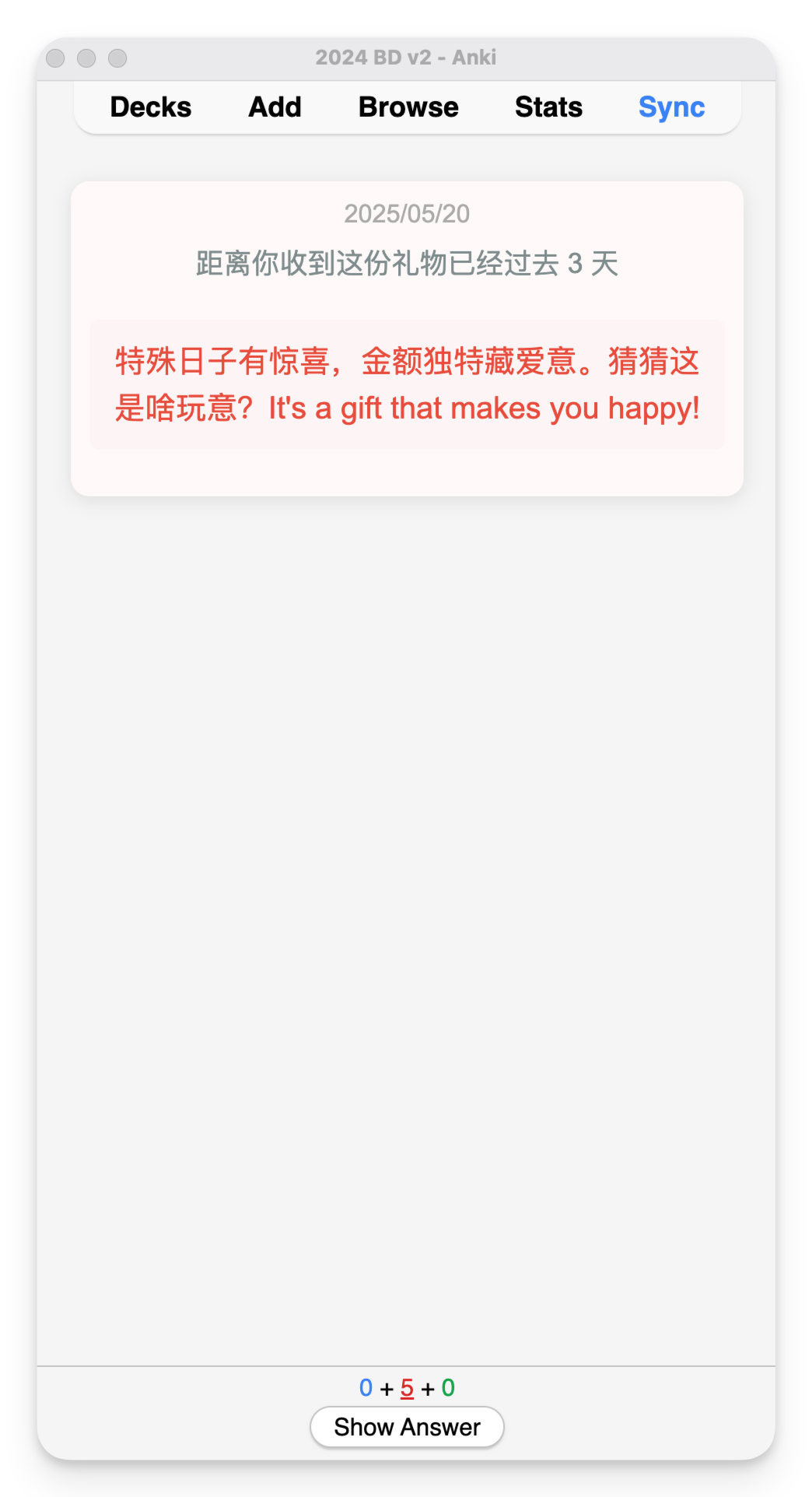
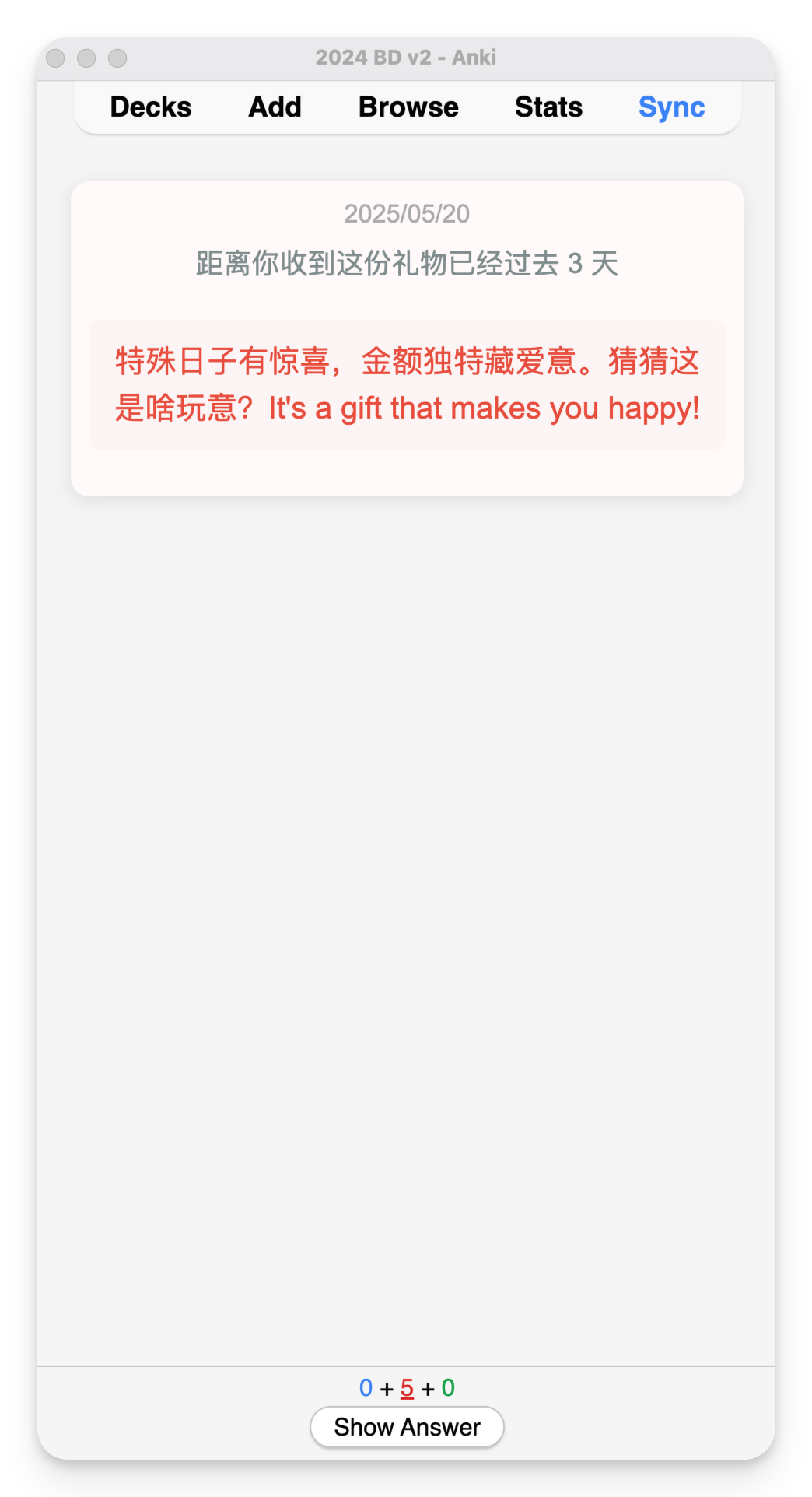
把触动瞬间,变成力量源泉 当我们有强烈想要实现的目标时, 往往能发掘出常见工具的新用途。 最近一年,我用这款通常用来「背单词」的 Anki 记忆软件,构建了一个专属自己的触动瞬间的「花园」。 我们的大脑总是偏向记住不愉快的事,让美好淡去。 手机照片堆积几千张, 那么多触动瞬间,没有多少被重新感受过。 若不刻意设计,日常生活的繁忙会让我的记忆力变成金鱼,那些瞬间的触动,变成沙滩上的脚印。 忙碌中,逐渐失去那些本该让我们感受到被爱与支持的珍贵记忆。 520521, 谐音的日子给大家表达情感的契机。送出和收到很多爱。(请允许我秀一下) 想象下,如果这些触动瞬间能完美保存,会是什么体验? 我们试图用多种方式保存这些记忆: 从物理相册到手机照片再到社交媒体。 不过却各有不足: - 相册落灰占地儿难以整理; - 手机照片被新内容表情包各类截图塞满; - 社交媒体更像是展示而非细致的触动记录。 最关键的是,它们没有主动回顾的机制。 人脑运作是单线程的,我们不能同时决定「应该回顾什么」和「完全沉浸在回顾中」这两件事。 且按照线性回顾顺序,内容变得可预测,失去新鲜感和惊喜。 Anki 这款高度自定义化的间歇性复习软件, 刚好完美解决了以上的问题。 它用算法接管「选择回顾什么」 的决策过程,让大脑只需专注于「体验回忆」本身。 Anki 原本用被来背诵单词和知识点,支持文字和图片作为载体。 这意味着我们可以用它来保存触动瞬间,并通过其动态复习算法,以随机且高效的方式回顾。 这也有缺点—— 因为是独属自己,高度定制化的触动瞬间和回忆,所以所有的卡片都必须自己制作。 但一次录入,永久存储, 主动推送回顾的模式让这项投入相当值得。 Anki 采用间隔重复算法,对记得好的卡片自动延长复习间隔,记得差的更频繁出现。这样每天只需复习少量卡片,却能高效巩固记忆。 设想一下, 如果从现在就养成这个习惯,那自己就真的会有个外置美好时刻触动瞬间 的记忆库。 「我会永远记住你」将并不再是一时上头的浪漫夸张,而会成为基于方法和工具的现实。 通过系统性地记录和复习,建立一个外部的、可靠的情感记忆系统,我能真正记住那些对我们关系而言重要的瞬间。 Richard Hamming提出过的问题 「Of all of life's burdens, which are those machines can relieve, or significantly ease, for us?」 (在生活的诸多负担中,哪些是机器可以为我们减轻或显著缓解的?) 记忆的流失正式这样的负担。 我们在珍藏触动时刻和应对遗忘的矛盾中, 而 Anki 这样的工具提供一种解决方案——把「什么时候该回顾什么」外包给机器,我们只需专注回顾。美好回忆的定期在大脑中重生。 于是我去年开始就在 Anki 中建立了相应的触动牌组。 分为三部分: Gathering Track: 和朋友们的见面记录, 有文字有图片 Gifts:朋友们送的礼物照片, 社媒晒不多,但我见它们有足够多次 Inspiring moments: 从网上看到触动的图片, 被夸奖的截图等等 当时还没有探索出来更快的制卡流程,都是手动制卡。 内容虽然少,但也非常值得。 以下是两张手动制作的极简卡片:朋友见面和收到的礼物🎁 制卡加上经常复习,感觉记忆得到了扩展, Andy Matuschak 提到过「 Spaced repetition systems can be used to program attention.」 (间歇重复系统可以用于对注意力进行编程。) 每天接触的信息也在塑造自己, 感觉自己整体上在有实际缘由地变得更乐观更积极,大脑中那些积极的神经回路频繁被点亮。 爱一定程度上是可以被存储的。 长期来看,这些Anki卡片构建了一个永恒的情感银行。珍贵瞬间不会消失,而是定期唤起记忆。 把复杂步骤,变成智能流程 经过一年的摸索和迭代,我构建了一套制卡工作流,让记录触动瞬间变清晰和顺畅。 制作时间缩短了90%以上,卡片文件大小也减少了90%。 大致步骤如下: 第一步:使用飞书智能表格捕捉瞬间 飞书智能表格作为数据中转站,通过问卷功能快速录入信息: - 创建一个包含"描述"、"图片"、"日期"等字段的表格 - 把表格变成问卷表单视图,录入更顺畅 - 还可以使用飞书AI功能自动生成额外内容,比如起个有趣的标题等 - 使用「插件市场」中的「导出Excel:内嵌图片」 插件, 下载成 Excel 文件 (录入问卷和表格示例如下) 第二步:图片处理与链接生成 - Anki卡片本质是HTML网页,直接嵌入图片会导致文件臃肿。更优方案是: - 使用Python脚本批量提取 Excel xlsx 文件中的图片(表述好需求,让ai写的,附在文章最后,供参考) - 将图片上传至图床(如Github仓库或七牛云) - 自动生成并保存图片链接到原 Excel xlsx 文件的单元格中 第三步:批量导入Anki - 在 Anki 提前设置一个卡片模板 - 将xlsx文件转成 CSV 格式。确保包含文字描述和图片链接 - 使用Anki的导入功能批量创建卡片 这套工作流的核心优势在于: - 轻量化 - Anki卡片本质是HTML网页,使用图片链接而非直接嵌入图片,大大减小了文件体积,同步也更快 - 高效率 - 借助飞书智能表格作为卡片数据库的中转站,录入流程和批量处理都非常迅速 - 长期可行 - 基于开源软件和成熟技术,理论上可以永久使用 对于编程小白,Python脚本可能听起来有些复杂,但借助现代AI工具,只需清晰表达需求,一步步测试运行生成的代码即可,无需深入理解编程细节。 不是特别私人的文件,我把Github 仓库作为图床,而和朋友见面、礼物等照片,我购买了七牛云的图床存储空间,两者效果是一样的。 Github 作为图床免费可靠就是加载速度有些慢。 另外结构性的表格可以批量迁移、编辑、关键词搜索等等,还有更多视图的展示。 以上的实现步骤复杂是因为涉及到了图片批量上传到图床。 如果只是纯文字内容, 使用飞书问卷先记录,后批量导入,完全不需要第二步,是非常容易的。 Anki 上手确实有些难度,不过可以它是开源项目,我们借助 DeepWiki 这个工具可以获得较为准确的教程 https://deepwiki.com/ankitects/anki 技术的意义不仅在于提高效率,更在于针对自己的目标,把它们当做实现的工具。 听上去好玩的话,或许今天就可以试试: 1、今天就下载安装Anki软件,它在非苹果设备上都是免费的 2、找到手机中一张让自己触动的图片 3、花十分钟时间创建第两张Anki卡片,最基础的就好 迈出了第一步,开始构建自己的情感记忆库。 如果觉得很赞,后续可以慢慢优化自己的流程,降低制卡阻力。 这个记忆系统最大的价值不是冻结过去,而是帮助我们从过去汲取力量,塑造更有意义的现在与未来。 自动提取含Excel文件中的图片上传到 Github 并将图片链接替换掉原单元格中的 仅供参考,更具体请问 ai 具体路径有些长,之后或许会写更详细的分享~但这件事对我来说很值得! 也👏🏻欢迎来这里: cupaobaidou.com baidou.work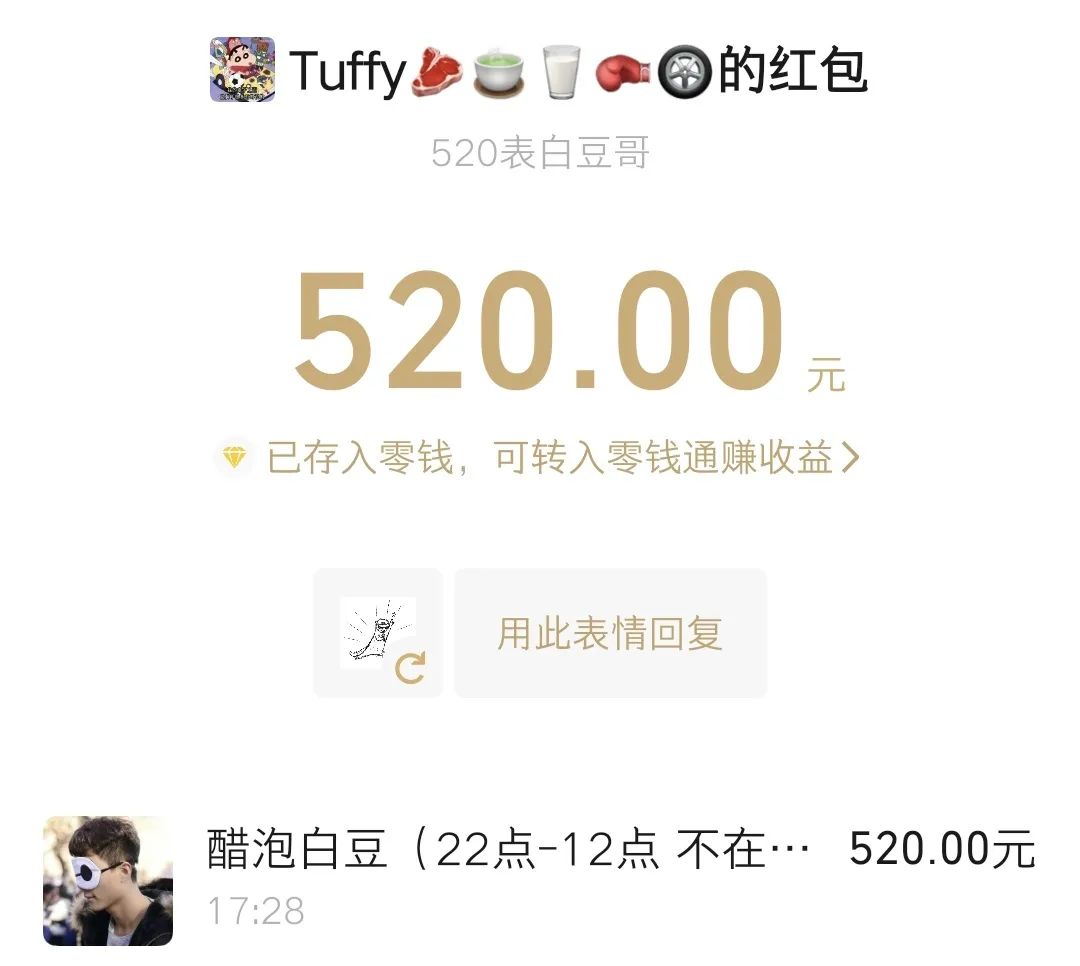



"""Excel图片提取与GitHub上传工具此工具可以从Excel文件中提取所有图片,上传到GitHub作为图床,然后生成一个新的Excel文件,将原图片替换为GitHub上的图片URL链接。功能特点:- 自动提取Excel中的所有嵌入图片及其位置信息- 批量上传图片到GitHub仓库- 生成新的Excel文件,保留原数据但替换图片为URL- 支持断点续传,可在上传中断后继续- 在新Excel中自动生成图片索引表使用前需要:1. 创建GitHub个人访问令牌: Settings > Developer settings > Personal access tokens > Fine-grained tokens - 选择 'Contents' 权限 (Read and write) 2. 创建config.ini文件,内容如下: [github] username = 你的GitHub用户名 repo = 用于存储图片的仓库名 token = 你的个人访问令牌 branch = main安装依赖:pip install openpyxl pillow requests使用方法:1. 配置config.ini2. 运行脚本3. 在弹出窗口中选择Excel文件4. 等待处理完成作者: 醋泡白豆+Claude3.7"""import osimport timeimport tempfileimport shutilfrom pathlib import Pathfrom datetime import datetimeimport openpyxlfrom openpyxl.utils import get_column_letterimport requestsfrom tkinter import Tk, filedialog, messageboxfrom PIL import Imageimport ioimport zipfileimport xml.etree.ElementTree as ETimport base64import jsonimport reimport pickleimport randomimport configparser# ===== 配置加载 =====defload_config(): """加载GitHub配置信息""" config = { 'username': '', 'repo': '', 'token': '', 'branch': 'main' } # 尝试从config.ini加载 cfg = configparser.ConfigParser() if os.path.exists('config.ini'): cfg.read('config.ini') if'github'in cfg: config['username'] = cfg['github'].get('username', '') config['repo'] = cfg['github'].get('repo', '') config['token'] = cfg['github'].get('token', '') config['branch'] = cfg['github'].get('branch', 'main') # 尝试从环境变量加载(优先级更高) config['username'] = os.environ.get('GH_USERNAME', config['username']) config['repo'] = os.environ.get('GH_REPO', config['repo']) config['token'] = os.environ.get('GH_TOKEN', config['token']) config['branch'] = os.environ.get('GH_BRANCH', config['branch']) # 验证配置 missing = [] ifnot config['username']: missing.append('GitHub用户名') ifnot config['repo']: missing.append('GitHub仓库名') ifnot config['token']: missing.append('GitHub访问令牌') return config, missing# ===== 重试配置 =====MAX_RETRIES = 3 # 上传失败时最大重试次数RETRY_DELAY = 5 # 重试间隔秒数RATE_LIMIT_DELAY = 10 # 请求过多时等待秒数defget_column_letter(col_idx): """将列索引转换为Excel列字母(1->A, 2->B, ...)""" result = "" while col_idx > 0: col_idx, remainder = divmod(col_idx - 1, 26) result = chr(65 + remainder) + result return resultdefextract_images_and_positions(excel_path): """ 从Excel文件中提取所有图片及其位置信息 使用直接解析drawing XML的方法获取精确位置 """ images_info = [] position_info = {} # 图片名 -> 位置信息 temp_dir = tempfile.mkdtemp() try: print("从Excel文件中提取图片并分析位置...") # 解压Excel文件到临时目录 with zipfile.ZipFile(excel_path, 'r') as zip_ref: zip_ref.extractall(temp_dir) # 1. 获取工作表信息 wb_xml_path = os.path.join(temp_dir, 'xl', 'workbook.xml') wb_xml = ET.parse(wb_xml_path) wb_root = wb_xml.getroot() # 提取所有工作表信息 sheets_info = {} # sheet_id -> sheet_name ns = {'': 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'} for sheet_elem in wb_root.findall('.//sheets/sheet', ns): sheet_id = sheet_elem.get('sheetId') sheet_name = sheet_elem.get('name') r_id = sheet_elem.get('{http://schemas.openxmlformats.org/officeDocument/2006/relationships}id') sheets_info[r_id] = {'id': sheet_id, 'name': sheet_name} print(f"找到工作表: ID={sheet_id}, 名称={sheet_name}, 关系ID={r_id}") # 2. 获取工作表与文件名的映射 rels_path = os.path.join(temp_dir, 'xl', '_rels', 'workbook.xml.rels') rels_xml = ET.parse(rels_path) rels_root = rels_xml.getroot() # 工作表ID与文件的映射 sheet_files = {} # r_id -> sheet xml path for rel in rels_root.findall('.//{http://schemas.openxmlformats.org/package/2006/relationships}Relationship'): r_id = rel.get('Id') target = rel.get('Target') if'worksheets/sheet'in target: sheet_files[r_id] = os.path.join(temp_dir, 'xl', target) print(f"工作表关系: ID={r_id}, 文件={target}") # 3. 处理每个工作表的drawing文件 for r_id, sheet_info in sheets_info.items(): sheet_name = sheet_info['name'] print(f"分析工作表: {sheet_name}") if r_id notin sheet_files: print(f" 找不到工作表 {sheet_name} 的文件") continue sheet_path = sheet_files[r_id] ifnot os.path.exists(sheet_path): print(f" 工作表文件不存在: {sheet_path}") continue # 查找工作表中的drawing引用 sheet_xml = ET.parse(sheet_path) sheet_root = sheet_xml.getroot() drawing_rid = None drawing_elem = sheet_root.find('.//drawing', {'': 'http://schemas.openxmlformats.org/spreadsheetml/2006/main'}) if drawing_elem isnotNone: drawing_rid = drawing_elem.get('{http://schemas.openxmlformats.org/officeDocument/2006/relationships}id') print(f" 工作表 {sheet_name} 有绘图元素,关系ID: {drawing_rid}") if drawing_rid isNone: print(f" 工作表 {sheet_name} 没有绘图元素") continue # 获取drawing文件的路径 sheet_dir = os.path.dirname(sheet_path) sheet_rels_path = os.path.join(sheet_dir, '_rels', os.path.basename(sheet_path) + '.rels') ifnot os.path.exists(sheet_rels_path): print(f" 工作表关系文件不存在: {sheet_rels_path}") continue sheet_rels_xml = ET.parse(sheet_rels_path) sheet_rels_root = sheet_rels_xml.getroot() drawing_path = None for rel in sheet_rels_root.findall('.//{http://schemas.openxmlformats.org/package/2006/relationships}Relationship'): if rel.get('Id') == drawing_rid: target = rel.get('Target') # 修正路径解析 if target.startswith('../'): # 相对路径,需要从sheet目录向上 base_dir = os.path.dirname(sheet_dir) rel_target = target[3:] # 去掉开头的 '../' drawing_path = os.path.join(base_dir, rel_target) else: # 直接路径 drawing_path = os.path.join(sheet_dir, target) break if drawing_path isNoneornot os.path.exists(drawing_path): print(f" 找不到drawing文件: {drawing_path}") continue print(f" 找到drawing文件: {os.path.basename(drawing_path)}") # 解析drawing文件获取图片位置 drawing_xml = ET.parse(drawing_path) drawing_root = drawing_xml.getroot() # 获取drawing文件与图片的关系 drawing_dir = os.path.dirname(drawing_path) drawing_rels_path = os.path.join(drawing_dir, '_rels', os.path.basename(drawing_path) + '.rels') ifnot os.path.exists(drawing_rels_path): print(f" drawing关系文件不存在: {drawing_rels_path}") print(f" 尝试在其他位置查找drawing关系文件...") # 尝试其他可能的路径 alt_rels_path = os.path.join(temp_dir, 'xl', 'drawings', '_rels', os.path.basename(drawing_path) + '.rels') if os.path.exists(alt_rels_path): drawing_rels_path = alt_rels_path print(f" 找到替代的drawing关系文件: {alt_rels_path}") ifnot os.path.exists(drawing_rels_path): print(f" 无法找到drawing关系文件,跳过图片位置分析") continue drawing_rels_xml = ET.parse(drawing_rels_path) drawing_rels_root = drawing_rels_xml.getroot() # 创建关系ID到图片路径的映射 image_rels = {} # rel_id -> image_path for rel in drawing_rels_root.findall('.//{http://schemas.openxmlformats.org/package/2006/relationships}Relationship'): r_id = rel.get('Id') target = rel.get('Target') if'../media/'in target or target.endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp')): image_name = os.path.basename(target) image_rels[r_id] = image_name print(f" 图片关系: ID={r_id}, 文件名={image_name}") # 分析drawing文件中的每个图片锚点 ns = { 'xdr': 'http://schemas.openxmlformats.org/drawingml/2006/spreadsheetDrawing', 'a': 'http://schemas.openxmlformats.org/drawingml/2006/main', 'r': 'http://schemas.openxmlformats.org/officeDocument/2006/relationships' } # 处理多种类型的锚点 for anchor_type in ['xdr:twoCellAnchor', 'xdr:oneCellAnchor']: for anchor in drawing_root.findall(f'.//{anchor_type}', ns): # 获取from位置 (左上角) from_elem = anchor.find('.//xdr:from', ns) if from_elem isNoneand anchor_type == 'xdr:oneCellAnchor': # oneCellAnchor可能直接包含位置信息 from_elem = anchor.find('.//xdr:pos', ns) if from_elem isnotNone: print(f" 找到oneCellAnchor位置元素") if from_elem isNone: print(f" 锚点没有from元素,跳过") continue # 变量初始化 from_col = None from_row = None # 对于twoCellAnchor if anchor_type == 'xdr:twoCellAnchor': col_elem = from_elem.find('.//xdr:col', ns) row_elem = from_elem.find('.//xdr:row', ns) if col_elem isNoneor row_elem isNone: print(f" 锚点missing行或列信息,跳过") continue from_col = int(col_elem.text) from_row = int(row_elem.text) # 获取to位置 (右下角) to_elem = anchor.find('.//xdr:to', ns) if to_elem isnotNone: to_col = int(to_elem.find('.//xdr:col', ns).text) to_row = int(to_elem.find('.//xdr:row', ns).text) else: to_col = from_col to_row = from_row # 对于oneCellAnchor elif anchor_type == 'xdr:oneCellAnchor': # 尝试获取from元素中的行列信息 col_elem = from_elem.find('./xdr:col', ns) row_elem = from_elem.find('./xdr:row', ns) if col_elem isnotNoneand row_elem isnotNone: from_col = int(col_elem.text) from_row = int(row_elem.text) to_col = from_col to_row = from_row else: # 如果没有行列信息,尝试获取ext元素中的尺寸信息 ext_elem = anchor.find('.//xdr:ext', ns) if ext_elem isnotNone: # 获取客户端数据 client_data = anchor.find('.//xdr:clientData', ns) if client_data isnotNone: print(f" 包含客户端数据") # 获取图片对象索引 img_index = 0 for i, an inenumerate(drawing_root.findall(f'.//{anchor_type}', ns)): if an == anchor: img_index = i break # 使用索引生成位置 from_row = img_index from_col = 0 # 第一列 to_row = from_row to_col = from_col # 获取图片信息 pic_elem = anchor.find('.//xdr:pic', ns) if pic_elem isNone: print(f" 锚点没有pic元素,跳过") continue blip_elem = pic_elem.find('.//a:blip', ns) if blip_elem isNone: print(f" pic元素没有blip子元素,跳过") continue embed_attr = '{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed' embed = blip_elem.get(embed_attr) if embed isNone: print(f" blip元素没有embed属性,跳过") continue print(f" 找到图片引用: {embed}") if embed notin image_rels: print(f" 图片引用 {embed} 不在关系映射中,跳过") continue image_name = image_rels[embed] # 确保from_col和from_row已定义 if from_col isnotNoneand from_row isnotNone: cell_address = f"{get_column_letter(from_col+1)}{from_row+1}" print(f" 图片 {image_name} 位置: {sheet_name}!{cell_address}") position_info[image_name] = { 'sheet': sheet_name, 'cell': cell_address, 'row': from_row+1, 'col': from_col+1, 'to_row': to_row+1if'to_row'inlocals() else from_row+1, 'to_col': to_col+1if'to_col'inlocals() else from_col+1 } else: print(f" 无法确定图片 {image_name} 的位置") # 4. 提取图片文件 media_dir = os.path.join(temp_dir, 'xl', 'media') if os.path.exists(media_dir): image_files = [f for f in os.listdir(media_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg', '.gif', '.bmp'))] print(f"从Excel中提取 {len(image_files)} 个图片文件") # 如果我们没有找到任何位置信息,但是drawing文件存在, # 可能是Excel特殊格式,尝试简单地映射图片1-n到工作表的A1-An单元格 ifnot position_info andlen(image_files) > 0: print("未找到图片位置信息,尝试自动分配位置...") # 获取第一个工作表名称 first_sheet_name = next(iter(sheets_info.values()))['name'] if sheets_info else"Sheet1" # 为每个图片分配一个位置 for i, img_file inenumerate(sorted(image_files)): row = i + 1 col = 1 # A列 cell_address = f"{get_column_letter(col)}{row}" position_info[img_file] = { 'sheet': first_sheet_name, 'cell': cell_address, 'row': row, 'col': col, 'to_row': row, 'to_col': col } print(f" 自动分配图片 {img_file} 位置: {first_sheet_name}!{cell_address}") for img_file in image_files: img_path = os.path.join(media_dir, img_file) try: image = Image.open(img_path) # 创建图片信息对象 img_info = { 'image': image, 'filename': img_file } # 添加位置信息 if img_file in position_info: img_info.update(position_info[img_file]) else: print(f" 未找到图片 {img_file} 的位置信息") images_info.append(img_info) print(f" 成功处理图片: {img_file}") except Exception as e: print(f" 处理图片 {img_file} 时出错: {str(e)}") else: print("未找到Excel中的media目录") except Exception as e: print(f"分析Excel文件时出错: {str(e)}") import traceback traceback.print_exc() finally: try: shutil.rmtree(temp_dir) except: pass return images_infodefcreate_github_folder(repo_owner, repo_name, folder_path, token, branch="main"): """在GitHub仓库中创建文件夹(通过创建一个.gitkeep文件)""" url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/contents/{folder_path}/.gitkeep" headers = { "Authorization": f"token {token}", "Accept": "application/vnd.github.v3+json" } data = { "message": f"Create folder {folder_path}", "content": base64.b64encode(b"").decode('utf-8'), "branch": branch } for attempt inrange(MAX_RETRIES): try: response = requests.put(url, headers=headers, data=json.dumps(data), timeout=30) if response.status_code in [201, 200]: # 201 Created, 200 OK print(f"成功创建文件夹: {folder_path}") returnTrue elif response.status_code == 422: # 文件可能已存在 print(f"文件夹可能已存在: {folder_path}") returnTrue elif response.status_code == 403and'rate limit'in response.text.lower(): wait_time = RATE_LIMIT_DELAY * (attempt + 1) print(f"达到API限制,等待{wait_time}秒...") time.sleep(wait_time) else: print(f"创建文件夹失败 (尝试 {attempt+1}/{MAX_RETRIES}): {response.status_code}{response.text}") time.sleep(RETRY_DELAY) except Exception as e: print(f"创建文件夹时出错 (尝试 {attempt+1}/{MAX_RETRIES}): {str(e)}") time.sleep(RETRY_DELAY) print(f"无法创建文件夹 {folder_path},但将继续尝试上传") returnFalsedefupload_to_github_with_retry(image_data, image_name, repo_owner, repo_name, repo_path, token, branch="main"): """将图片上传到GitHub仓库,包含重试机制""" # 创建临时文件保存图片 temp_dir = tempfile.mkdtemp() temp_path = os.path.join(temp_dir, image_name) image_data.save(temp_path) # 读取图片文件内容 withopen(temp_path, 'rb') as f: content = f.read() # 清理临时文件 try: os.remove(temp_path) os.rmdir(temp_dir) except: pass # Base64编码图片内容 content_b64 = base64.b64encode(content).decode('utf-8') # 构建API请求 url = f"https://api.github.com/repos/{repo_owner}/{repo_name}/contents/{repo_path}/{image_name}" headers = { "Authorization": f"token {token}", "Accept": "application/vnd.github.v3+json" } data = { "message": f"Upload image {image_name}", "content": content_b64, "branch": branch } # 添加重试机制 for attempt inrange(MAX_RETRIES): try: response = requests.put(url, headers=headers, data=json.dumps(data), timeout=60) if response.status_code in [201, 200]: # 201 Created, 200 OK returnf"https://raw.githubusercontent.com/{repo_owner}/{repo_name}/{branch}/{repo_path}/{image_name}" elif response.status_code == 403and'rate limit'in response.text.lower(): wait_time = RATE_LIMIT_DELAY * (attempt + 1) print(f"达到API限制,等待{wait_time}秒...") time.sleep(wait_time) else: print(f"上传失败 (尝试 {attempt+1}/{MAX_RETRIES}): {response.status_code}{response.text}") time.sleep(RETRY_DELAY) except Exception as e: print(f"上传过程中出错 (尝试 {attempt+1}/{MAX_RETRIES}): {str(e)}") time.sleep(RETRY_DELAY) raise Exception(f"上传失败,已达到最大重试次数({MAX_RETRIES})")defcreate_excel_with_urls(original_excel_path, images_info, urls): """创建带有URL的Excel文件,移除原始图片""" # 读取原始Excel文件 wb = openpyxl.load_workbook(original_excel_path) # 创建URL映射:sheet_name -> cell_address -> url url_map = {} index_data = [] # 保存URL索引数据 for i, (info, url) inenumerate(zip(images_info, urls)): if url isNone: # 跳过上传失败的图片 continue sheet_name = info.get('sheet') cell_address = info.get('cell') filename = info.get('filename', f"图片{i+1}") # 保存到索引数据 index_data.append({ 'index': i+1, 'filename': filename, 'location': f"{sheet_name}!{cell_address}"if sheet_name and cell_address else"未知", 'url': url }) # 如果有有效的工作表和单元格地址 if sheet_name and cell_address: if sheet_name notin url_map: url_map[sheet_name] = {} url_map[sheet_name][cell_address] = url # 移除所有工作表中的图片 print("移除原始Excel中的图片...") for sheet_name in wb.sheetnames: sheet = wb[sheet_name] ifhasattr(sheet, '_images'): sheet._images.clear() # 清除可能存在的drawing关系 ifhasattr(sheet, '_drawing'): sheet._drawing = None # 在原始工作表中放置URL urls_placed = False for sheet_name, cell_urls in url_map.items(): if sheet_name in wb.sheetnames: sheet = wb[sheet_name] print(f"在工作表 '{sheet_name}' 中放置URL") for cell_address, url in cell_urls.items(): try: cell = sheet[cell_address] cell.value = url print(f" URL放置在 {sheet_name}!{cell_address}: {url}") urls_placed = True except Exception as e: print(f" 放置URL到 {cell_address} 时出错: {str(e)}") # 创建索引表 index_sheet_name = "IMAGE_URLs" if index_sheet_name in wb.sheetnames: ws = wb[index_sheet_name] else: ws = wb.create_sheet(index_sheet_name) # 设置表头 ws['A1'] = "序号" ws['B1'] = "图片文件名" ws['C1'] = "位置" ws['D1'] = "图片URL" # 填充数据 for i, data inenumerate(index_data, 2): # 从第2行开始 ws[f'A{i}'] = data['index'] ws[f'B{i}'] = data['filename'] ws[f'C{i}'] = data['location'] ws[f'D{i}'] = data['url'] # 自动调整列宽 for col in ['A', 'B', 'C', 'D']: max_length = 0 for i inrange(1, len(index_data) + 2): # 包括表头和所有数据行 cell_value = ws[f'{col}{i}'].value if cell_value: max_length = max(max_length, len(str(cell_value))) adjusted_width = max_length + 2 ws.column_dimensions[col].width = adjusted_width # 保存新的Excel文件 original_path = Path(original_excel_path) new_excel_path = original_path.with_name(f"{original_path.stem}_with_urls{original_path.suffix}") # 尝试使用不同的保存模式以确保图片被移除 try: print("保存不包含图片的Excel文件...") wb.save(new_excel_path) except Exception as e: print(f"保存Excel时出错: {str(e)}") try: # 备用方法:创建新的Excel文件而不是修改现有文件 print("尝试备用方法保存Excel...") # 创建一个全新的工作簿 from openpyxl import Workbook new_wb = Workbook() # 删除默认创建的空白工作表 if"Sheet"in new_wb.sheetnames: del new_wb["Sheet"] # 复制所有工作表内容,但不包括图片 for sheet_name in wb.sheetnames: # 创建新工作表 new_sheet = new_wb.create_sheet(sheet_name) old_sheet = wb[sheet_name] # 复制单元格值和格式 for row in old_sheet.iter_rows(values_only=False): for cell in row: if cell.value isnotNone: new_sheet[cell.coordinate].value = cell.value # 设置列宽 for col in old_sheet.column_dimensions: new_sheet.column_dimensions[col].width = old_sheet.column_dimensions[col].width # 保存新工作簿 new_wb.save(new_excel_path) print(f"使用备用方法保存成功") except Exception as ex: print(f"备用保存方法也失败: {str(ex)}") return new_excel_pathdefsave_progress(folder_name, uploaded_images): """保存上传进度,用于断点续传""" try: progress_file = f"{folder_name}_progress.pkl" withopen(progress_file, 'wb') as f: pickle.dump(uploaded_images, f) print(f"进度已保存到文件: {progress_file}") except Exception as e: print(f"保存进度时出错: {str(e)}")defload_progress(folder_name): """加载上传进度,用于断点续传""" progress_file = f"{folder_name}_progress.pkl" try: if os.path.exists(progress_file): withopen(progress_file, 'rb') as f: uploaded_images = pickle.load(f) print(f"已加载上传进度,有 {len(uploaded_images)} 张图片已上传") return uploaded_images else: print("没有找到保存的进度,将从头开始上传") except Exception as e: print(f"加载进度时出错: {str(e)}") return {}defmain(): # 加载配置 config, missing = load_config() if missing: message = f"配置缺失: {', '.join(missing)}\n\n请检查config.ini文件或环境变量。" print(message) try: # 初始化tkinter root = Tk() root.withdraw() messagebox.showerror("配置错误", message) root.destroy() except: pass return # 设置GUI选择文件 root = Tk() root.title("Excel图片提取器 - GitHub版") root.withdraw() # 隐藏主窗口 # 设置初始目录为用户主目录 initial_dir = os.path.expanduser("~") # 让用户选择Excel文件 excel_path = filedialog.askopenfilename( title="选择Excel文件", filetypes=[("Excel files", "*.xlsx"), ("Excel files", "*.xls"), ("All files", "*.*")], initialdir=initial_dir ) ifnot excel_path: print("没有选择文件,程序退出") return # 关闭Tk窗口 root.destroy() print(f"\n开始处理文件: {excel_path}") try: # 创建新的文件夹名称,基于当前日期和时间 now = datetime.now() folder_name = now.strftime("excel_images_%Y%m%d_%H%M%S") # 检查是否有未完成的上传任务 resume_folder = None saved_progress_files = [f for f in os.listdir('.') if f.endswith('_progress.pkl')] if saved_progress_files: print("检测到有未完成的上传任务:") for i, f inenumerate(saved_progress_files): folder = f.replace('_progress.pkl', '') print(f" [{i+1}] {folder}") print(f" [0] 创建新任务: {folder_name}") choice = input("请选择要继续的任务编号,或输入0创建新任务: ") try: choice_idx = int(choice) if1 <= choice_idx <= len(saved_progress_files): resume_folder = saved_progress_files[choice_idx-1].replace('_progress.pkl', '') folder_name = resume_folder except: pass repo_path = folder_name uploaded_images = {} # 加载之前的进度 if resume_folder: uploaded_images = load_progress(folder_name) # 创建GitHub上的文件夹 create_github_folder(config['username'], config['repo'], repo_path, config['token'], config['branch']) # 提取图片和位置信息 print("正在提取图片和分析位置...") images_info = extract_images_and_positions(excel_path) print(f"共提取到 {len(images_info)} 张图片") ifnot images_info: print("没有找到图片,程序退出") return # 上传到GitHub print(f"正在上传图片到GitHub仓库: {config['username']}/{config['repo']}/{repo_path}") urls = [None] * len(images_info) # 预先填充None值 batch_size = 20 # 每批处理的图片数量 for batch_idx inrange(0, len(images_info), batch_size): batch_end = min(batch_idx + batch_size, len(images_info)) print(f"\n处理第 {batch_idx+1} 到 {batch_end} 张图片(共 {len(images_info)} 张)") for i inrange(batch_idx, batch_end): info = images_info[i] # 生成唯一的文件名 original_name = info.get('filename', f"image_{i+1}") safe_name = re.sub(r'[^\w.-]', '_', original_name) timestamp = int(time.time() * 1000) image_name = f"{safe_name}_{timestamp}.png" # 检查是否已上传此图片 if original_name in uploaded_images: print(f"跳过已上传的图片 ({i+1}/{len(images_info)}): {original_name}") urls[i] = uploaded_images[original_name] continue try: # 上传并获取URL url = upload_to_github_with_retry( info['image'], image_name, config['username'], config['repo'], repo_path, config['token'], config['branch'] ) urls[i] = url uploaded_images[original_name] = url print(f"上传进度: {i+1}/{len(images_info)} - {url}") # 每上传5张图片保存一次进度 if (i + 1) % 5 == 0: save_progress(folder_name, uploaded_images) # 添加短暂延迟避免API限制 time.sleep(random.uniform(1, 3)) except Exception as e: print(f"上传图片 {original_name} 失败: {str(e)}") save_progress(folder_name, uploaded_images) # 每批处理完保存进度 save_progress(folder_name, uploaded_images) # 批量处理后等待一段时间,避免API限制 if batch_end < len(images_info): print(f"批量处理完成,等待30秒后继续...") time.sleep(30) # 创建新的Excel文件 print("\n正在创建新的Excel文件...") new_excel_path = create_excel_with_urls(excel_path, images_info, urls) message = f"处理完成!新文件保存在: {new_excel_path}" print(message) # 显示完成信息 try: if os.name == 'posix': # macOS或Linux os.system(f"osascript -e 'display notification \"新文件保存在: {new_excel_path}\" with title \"处理完成\"'") elif os.name == 'nt': # Windows root = Tk() root.withdraw() messagebox.showinfo("处理完成", message) root.destroy() except: pass # 处理完成后,删除进度文件 progress_file = f"{folder_name}_progress.pkl" if os.path.exists(progress_file): try: os.remove(progress_file) print(f"已删除进度文件: {progress_file}") except: pass except Exception as e: error_message = f"处理过程中出错: {str(e)}" print(error_message) import traceback traceback.print_exc() try: root = Tk() root.withdraw() messagebox.showerror("错误", error_message) root.destroy() except: passif __name__ == "__main__": main()

果博东方客服开户联系方式【182-8836-2750—】?薇- cxs20250806】
果博东方公司客服电话联系方式【182-8836-2750—】?薇- cxs20250806】
果博东方开户流程【182-8836-2750—】?薇- cxs20250806】
果博东方客服怎么联系【182-8836-2750—】?薇- cxs20250806】
华纳东方明珠客服电话是多少?(▲18288362750?《?微信STS5099? 】
如何联系华纳东方明珠客服?(▲18288362750?《?微信STS5099? 】
华纳东方明珠官方客服联系方式?(▲18288362750?《?微信STS5099?
华纳东方明珠客服热线?(▲18288362750?《?微信STS5099?
华纳东方明珠24小时客服电话?(▲18288362750?《?微信STS5099? 】
华纳东方明珠官方客服在线咨询?(▲18288362750?《?微信STS5099?